NeurIPS 2025の感想
はじめに

- 全体的な感想:
- めちゃくちゃ人がいました。Virtualと現地含めて3万人近くらしいです。
- 数万人規模の会議になると偶然知り合いに遭遇するのは奇跡的な確率になるので1:1を事前もしくは会議中にお願いしたのは非常に良かったです。あと自分みたいな学生でも有名でもない人の話・質問でも意外と聞いてくれました。
- 自分が見聞きしたのはせいぜい50件、i.e., 50/5833 ~= 0.0086 = 0.86% と会議全体の非常に小さな部分しか見聞きできていないので、他の方々の印象とは180度違う可能性があるのでご留意ください。(ぜひ他の方々の感想も見聞きしたいです)。あと自分は言語処理・NLP系出身なので、全体的に画像・動画分野のポスター・発表は流し見だけしかしていません。

会議の感想・振り返り・学んだこと
- 1:1の設定
- 2023年までに自分が参加した*ACL系の会議では特に1:1は設定していなかったのですが、前お世話になった方がNAACL2022でやっていられるのを覚えていて、Virtualと現地含めて3万人近くの参加者のため、さすがに今回はやった方が良いと思い実践しました。
- 旧ツイッター上で#NeurIPS2025と検索すると結構「声かけてねー」と投稿されていた参加者がいらっしゃったので、自分のキャパを超えない程度に設定しました。
- 実は発表よりここで聞いた話が一番面白くて参考になりました。
- VC・企業スポンサーイベントの多さ
- 確かACL2019やNAACL2022等でもスポンサーのアフターパーティが開催されていたのは覚えているのですが、とにかく数が違います。
- 一番網羅的なのはこちらのsubstack postです。
- 実は動機としては二年程前に笠井さんのツイートを拝見し、直接お話も伺った後に「どれだけ*ACL系の会議と違うのだろう」と気になり始め、興味本位で今回行った次第です(昨年は転職活動で忙しかったため叶わず)。
- 実際現地に行ってみると、スポンサーのアフターパーティの数から見てもわかる通り、かなり雰囲気が違います。
- 企業ブースも企業ロゴのネオンやらが輝いていたり、動いていたり、とにかく「お金がかかっているなー」という印象です。
- 確かACL2019やNAACL2022等でもスポンサーのアフターパーティが開催されていたのは覚えているのですが、とにかく数が違います。
— Jungo Kasai (@JungoKasai) December 16, 2023

- 拡散言語モデルであるLLaDA 8Bとそれを使った研究が同時に発表
- NeurIPSでは拡散言語モデルをどうのようにして高速化するか、の発表が多かったです。詳しくは「人工知能は拡散言語モデルの夢を見るか?」やNeurIPSのScholar Inboxに発表論文があるのでここでは割愛します。
- 個人的な感想ですが、2019年NAACLでBERTが発表されましたが、2018年時点で既にバズっていたのでBERT自体の発表とその解析やBERTを使った論文が同じ会議で発表されたのを思い出しました。デジャブ。
- 言語モデルの大まかな歴史的な流れはn-gram言語モデル→ (SVM/CRF/LDA等で他のNLPタスクを解く) → word2vec/RNN→ LSTM→BERT(コレ)→GPT-1/2/3→ ChatGPT/GPT-3.5 → …という認識でこれから伸びていくステージか否か、はてさて
- NeurIPSのScholar Inboxではいいね数もみれるのですが、LLaDA 8Bは100以上いいねがついていてやはり人気な印象でした(ちなみにポスターセッションは人垣ができていたので諦めて他のポスターを聞いて回ってました。)
- 1:1をいくつかお願いしたのですが、その最中に紹介して頂いたUniform State Diffusion Modelに関する論文(NeurIPSではないけれども)が一番面白かったです。
- 思うにEMNLP 2023でProf. Chris Manningの招待講演がNeurIPS 2023で発表される予定のDirect Preference Optimizationが講演トピックの一つだったため、最近の会議では次の会議で発表される内容を聞く場所になりつつあるとあらためて実感しました。
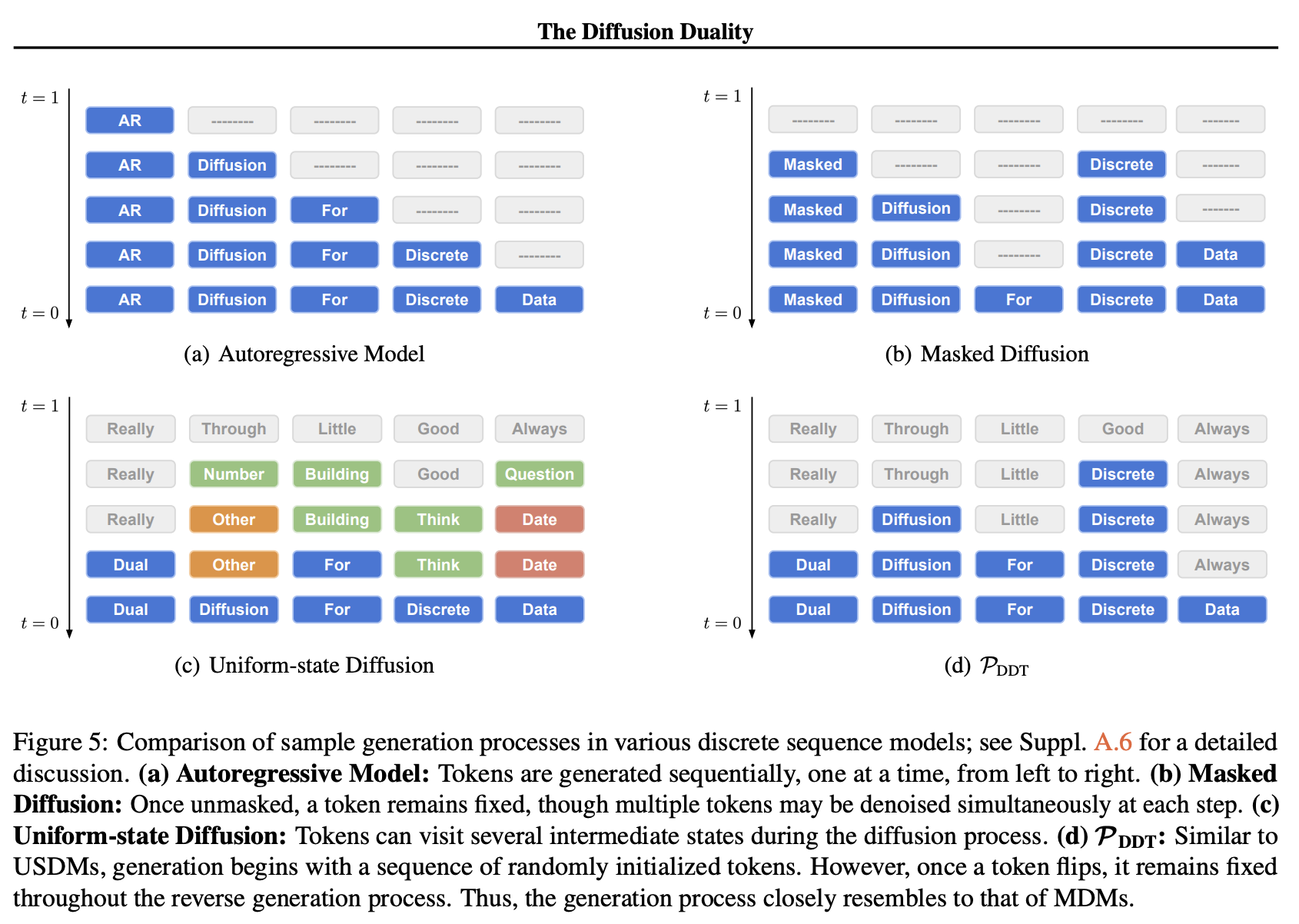
- Uniform State Diffusion Language Model
- LLaDAやDreamが自分が知っている中で一番バズった拡散言語モデルですが、それらはmasked diffusion (i.e., 文を生成する時の初期状態が全て[MASK]トークン)でありUniform-state diffusionは文の初期状態がモデルのvocabularyからランダムにサンプリングされたものです。
- 1:1にて著者の方に直接質問・ご説明頂きました。やはり直接説明して頂いた方が論文のどこに注目するべきか、その順番(left-to-rightではなく拡散言語モデルの推論と同じく結構random order)、裏話なども聞けて非常にわかりやすかったです。以下Publicになっていない情報は公開しないよう気をつけながら書いております)
- Uniform-State Diffusionだとre-masking(一度[MASK]トークンからそうでないものに遷移したトークンをもう一度[MASK]トークンに置換する方法)が自然にモデル化されています(そもそも[MASK]トークンを使っていない)。
- NeurIPS 2025でも発表されたReMDMとかがまさしくこのremaskingに関することです。
- (余談ですがこの時点でmasked diffusion modelがなぜabsorbing state diffusionと呼ばれるか理解しました。ブラックホールのように[MASK]トークンに吸収されるイメージで、その状態から遷移しないことが前提のためabsorbing state diffusionと呼ばれます)
- ちなみに会議と直接関係ありませんが拡散言語モデルに関しては徳永さんが書かれた拡散言語モデルと自己回帰モデルの間にはも面白かったです。uniform-state diffusionがこちらのブログの続きの一つ、というのが勝手なイメージです。
- 徳永さんの拡散言語モデルのPart 1のタイトル「人工知能は拡散言語モデルの夢を見るか?」でもある通り、拡散言語モデルが自己回帰モデルに本格的にとって変わってメジャーとなるのかならないのか、というのは現地参加者とも議論しましたが意見が結構割れていました。個人的な意見としては現在の拡散言語モデルは数年前の自己回帰モデルの状況(具体的にはLlama 1の学習がまだ不安定だった時代や、自己回帰モデルではないですが上でも書いたBERTなど)であると思っているので、今後数年で多くのオープンウェイトモデルや推論エンジンも整備されていき(e.g., SGLangがかなり積極的でおそらく他の推論エンジンも追随する)特に系列長が決まっているタンパク質設計、繰り返しが多く複数のトークンが自然言語よりも予測しやすいプログラムの生成や他の拡散言語モデルの性質と相性が良い分野のエージェントとして2026年以降に本格的に導入されていくのであろう、と予想しております。
- Model Merge関連
- 1日目のチュートリアルで印象に残ったのがこのModel Merge関連のチュートリアルです。前半部分はModel Merging: A Surveyの詳細を省いたものに近い印象だったので少々退屈でした。
- ただ、自分にとって学びになったのは混合エキスパートモデル(Mixture of Expert, MoE)のマージでした。チュートリアルでMoEのマージをMoErgingという名前をつけているのが、何というか「上手い」名付けという印象です。実際1日目に聞いたにも関わらず自分の頭にも残っています(ただ、会議中に一つMoErgingのポスターを聞いたため忘却曲線がリセットされています)。
- その他・Misc
- 昔WWW2016に聴講に行った時はあまり言語処理系の発表がなく、知り合いもあまりいなかったため、あまり面白くなかったですが、NeurIPSは個人的には面白かったです。特にLLMはもう画像、音声、ビデオ問わず、モジュールの一つとして組みこまれているので、関係ない発表があまりなかったです。
最後に
現地でお会い・お話・議論してくださった方々、ありがとうございました。
お仕事・共同研究募集中です
2025年7月に米国永住権であるグリーンカードを取得したため、ようやくビザの制約から解放されて仕事・案件・共同研究を募集中です。ご興味のある方はfujinumay at gmail dot comまでお待ちしております。
Enjoy Reading This Article?
Here are some more articles you might like to read next: