Random Thoughts on NeurIPS 2025
Introduction

- General impressions:
- People, People, and People! Nearly 30,000 participants including virtual and in-person attendance.
- At a conference of tens of thousands of people, encountering someone you know by chance becomes nearly miraculous, so scheduling 1:1 meetings in advance or during the conference was extremely beneficial. Also, even as a graduate student who isn’t famous, people were surprisingly willing to listen to my talks and questions.
- Please note that I only saw or heard about roughly 50 presentations, i.e., 50/5833 ~= 0.0086 = 0.86% of the entire conference, so my impressions might be completely different from others’ (I’d love to hear others’ thought as well). Also, since I come from an NLP background, I only skimmed through image and video-related posters and presentations.

Conference Reflections, Learnings, and Takeaways
- Setting up 1:1 meetings was a HUGE success for me
- At *ACL conferences I attended until 2023, I didn’t set up 1:1 meetings, but I remembered someone I previously worked with doing this at NAACL 2022. With nearly 30,000 participants (virtual and in-person), I thought it would definitely be worthwhile this time and put it into practice.
- Searching for #NeurIPS2025 on Twitter/X, I found quite a few participants posting “feel free to reach out!” kind of post, so I reached out to some folks to set up 1:1 hallway chat (but kept within my capacity to handle it).
- The conversations I had during these 1:1s were actually the most interesting and informative part of the conference, even more than the presentations.
- The abundance of VC and corporate sponsor events
- I remember after-parties hosted by sponsors at ACL 2019, but the sheer number at NeurIPS was on a different scale.
- The most comprehensive list is in this substack post.
- Actually, my motivation for attending came from seeing Jungo Kasai’s tweet about two years ago and speaking with him directly. I became curious about “how different is this from *ACL conferences?” and decided to attend this year out of curiosity (I was too busy with job hunting last year to make it).
- Having actually attended in person, as you can see from the number of sponsor after-parties, the atmosphere is quite different from *ACL conferences.
- The corporate booths had neon company logos glowing and moving, giving the overall impression of “a lot of money has been spent here.”
- I remember after-parties hosted by sponsors at ACL 2019, but the sheer number at NeurIPS was on a different scale.

- Simultaneous presentations of the diffusion language model LLaDA 8B and papers building on top of it
- At NeurIPS, there were many presentations on how to accelerate diffusion language models. For details, see the papers on NeurIPS’s Scholar Inbox, so I’ll omit the details here.
- It reminded me of NAACL 2019 when BERT was presented, but it had already been buzzing since the arXiv/Github debut in 2018, so BERT itself, its analysis, and papers using BERT were all presented at the same conference. Déjà vu.
- On a side note, the history of language models is: n-gram language models → (solving other NLP tasks with SVM/CRF/LDA, etc.) → word2vec/RNN → LSTM → BERT (this one) → GPT-1/2/3 → ChatGPT/GPT-3.5 → … and more to come for diffusion language models!
- On NeurIPS’s Scholar Inbox, you can see the number of likes, and LLaDA 8B had over 100 likes, giving the impression of being quite popular (incidentally, there was such a crowd at the poster session that I gave up and went to listen to other posters).
- I requested several 1:1 meetings. The most interesting paper mentioned during my 1:1s was the paper on Uniform State Diffusion Model (not from NeurIPS though) which was introduced to me during one of them.
- It also reminded of Prof. Chris Manning’s invited talk at EMNLP 2023 which covered Direct Preference Optimization and later presented at NeurIPS 2023. I realized once again that recent conferences are becoming places to hear about content that will be presented at the next conference.
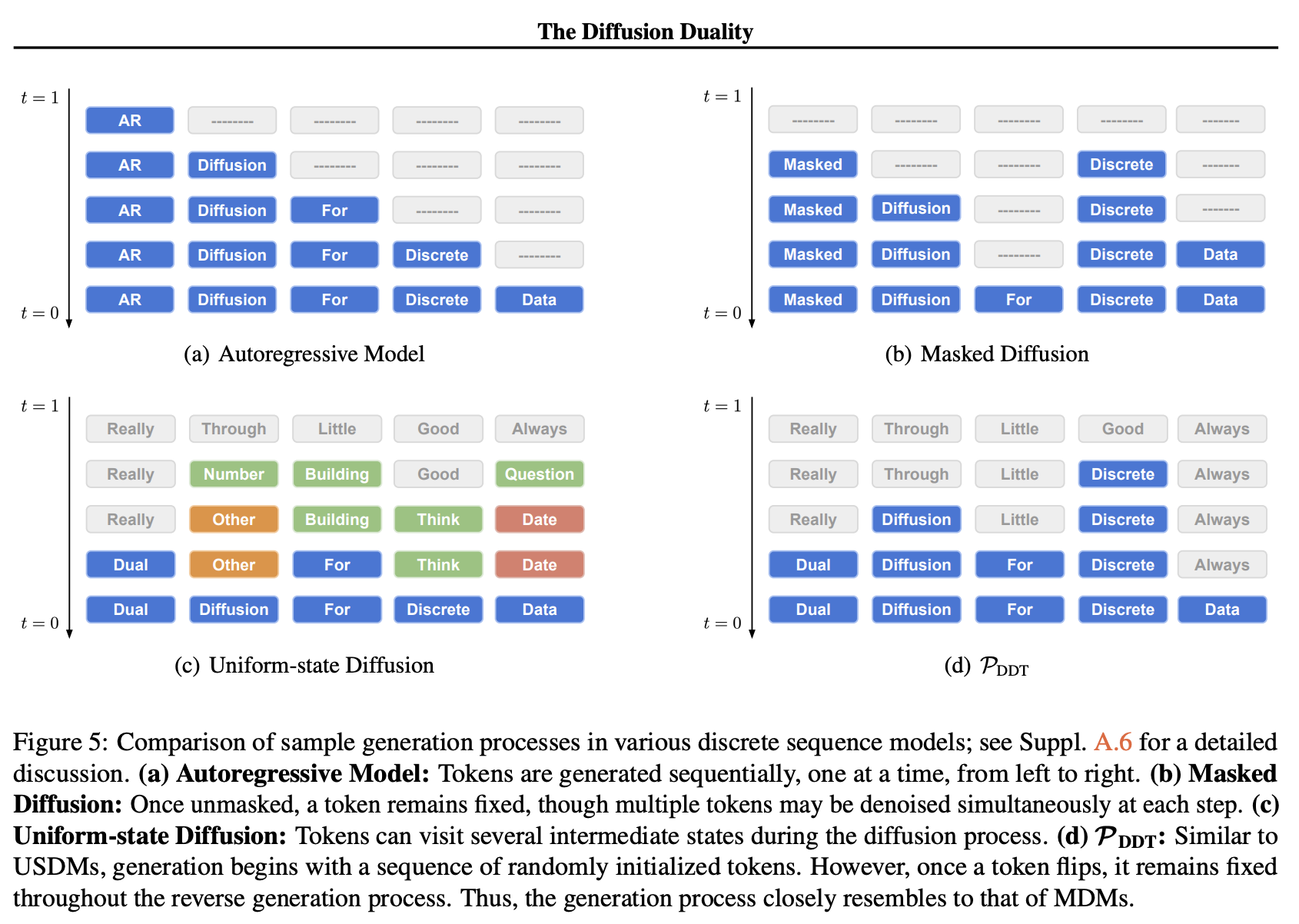
- Uniform State Diffusion Language Model
- LLaDA and Dream are the most buzzed diffusion language models I know of, but they are masked diffusion (i.e., the initial state when generating a sentence is all [MASK] tokens), whereas Uniform-state diffusion has an initial sentence state that is randomly sampled from the model’s vocabulary.
- I asked questions and received explanations directly from the author during a 1:1 meeting. Having it explained directly was indeed much clearer in terms of which parts of the paper to focus on, the order (not left-to-right but quite random order, same as the inference of diffusion language models), and behind-the-scenes stories. (Not disclosing here just in case since this is non-public.)
- Uniform-State Diffusion naturally models re-masking (the method of replacing tokens that have once transitioned from [MASK] tokens to non-mask tokens back to [MASK] tokens again, although it does not use [MASK] tokens to begin with).
- ReMDM, which was also presented at NeurIPS 2025, is exactly about this remasking.
- (At this point I understood why masked diffusion models are called absorbing state diffusion. Like a black hole, they are absorbed into the [MASK] token, and because the assumption is that they don’t transition from that state, they are called absorbing state diffusion.)
- Not directly related to the conference, but Between Diffusion Language Models and Autoregressive Models (In Japanese) was a good read. My personal impression is that uniform-state diffusion is one possible next topic of this blog.
- I discussed with participants on-site whether diffusion language models will fully replace autoregressive models and become mainstream, and opinions were quite divided. My personal opinion is that current diffusion language models are at the stage of autoregressive models from a few years ago (specifically, the era when Llama 1 training was still unstable, or BERT, which isn’t an autoregressive model but as I mentioned above). My prediction is that over the next few years, many open-weight models and inference engines will be developed (e.g., SGLang is currently in full steam) and introduced in earnest from 2026 onwards as agents in fields where diffusion language models’ properties are compatible, such as protein design where sequence length is fixed, program generation where repetition is common and multiple tokens are more predictable than natural language, and many other fields!
- Model Merge-related topics
- The tutorial on Model Merge on Day 1 was pretty nice. The first half seemed similar to what I saw in Model Merging: A Survey.
- What was most educational for me was the merging of Mixture of Expert (MoE) models. Naming MoE merging “MoErging” as mentioned in the tutorial is a very nice choice :) It actually stuck in my head even though I heard it on Day 1 (although the forgetting curve was reset because I attended one MoErging poster during the conference).
- The impression was that they were breaking down A Survey on Model MoErging: Recycling and Routing Among Specialized Experts for Collaborative Learning.
- Other/Misc
- When I attended WWW2016 as an auditor in the past, there weren’t many NLP presentations and I didn’t know many people, so it wasn’t that interesting for me back in that time, but this year’s NeurIPS was very interesting for me. Especially since LLMs are now incorporated as modules regardless of whether they’re for images, audio, or video, there were hardly any irrelevant presentations.
Final Remark
Thank you to everyone who met, talked, and discussed with me on-site.
Also, big thank you to the attendants and presenters who tried their best to speak English even if it’s not their first language during the poster presentations. Very much appreciated. I also did my best not to speak Japanese during poster presentations.
Finally, if you are looking for someone to collaborate with, don’t hesitate to contact me at fujinumay at gmail dot com!
Enjoy Reading This Article?
Here are some more articles you might like to read next: